This work was done while working as a Research Fellow with PIBBSS (2025) with Stefan Heimersheim.
LLMs perform nonlinear mappings from their inputs to their outputs—some of these nonlinearities are built into the architecture, but others are learned, and may be important parts of how models represent and transform information. In this project, I studied one such learned nonlinearity: activation plateaus.
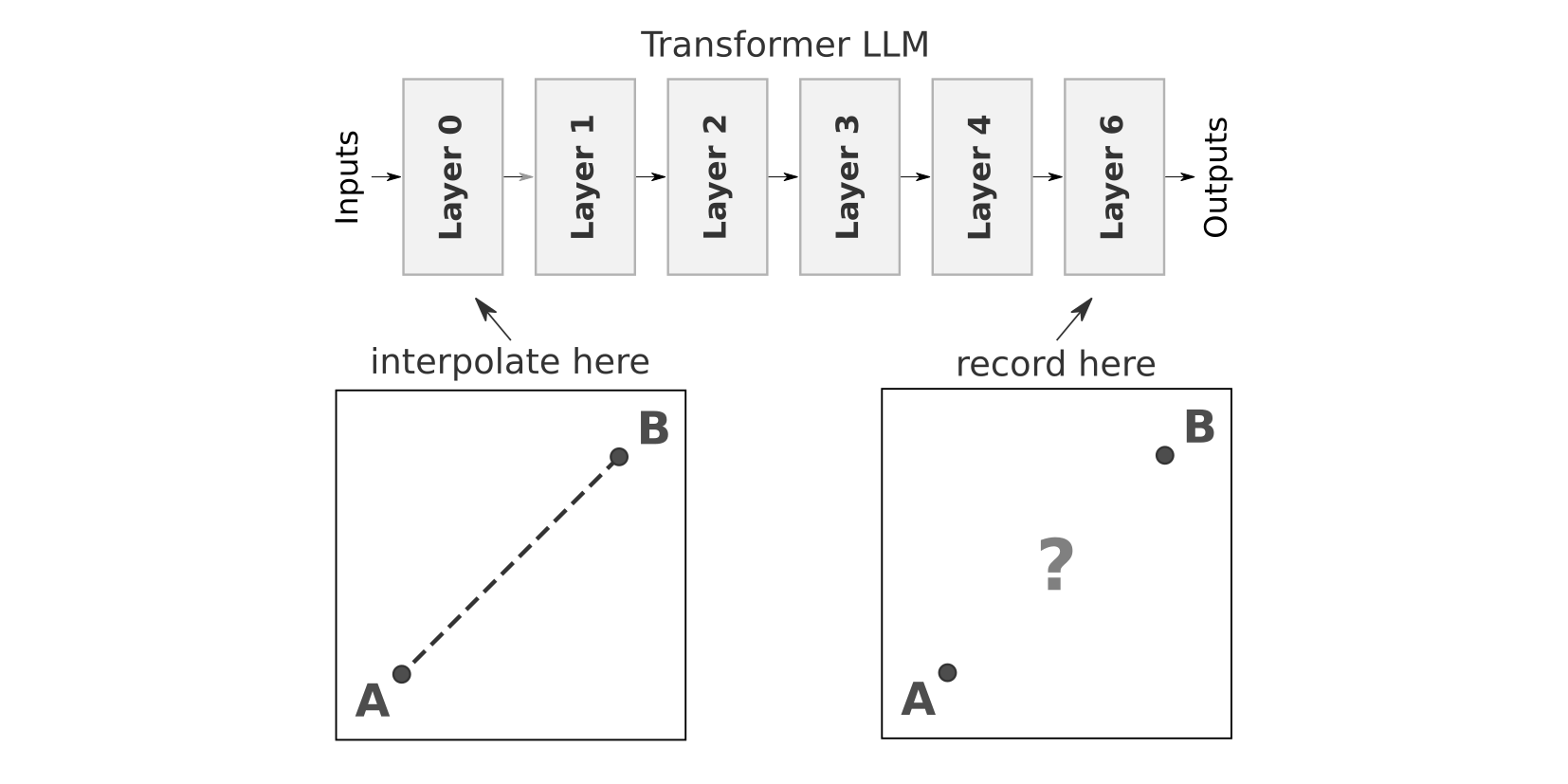
Activation plateaus are a phenomenon where smoothly interpolating between two input sequences produces minimal downstream changes for most of the interpolation, with a sudden rapid “phase change” somewhere in the middle. The basic setup is straightforward: take two text sequences that are identical except for the last token (e.g. “The house was big” and “The house was in”), collect activations early in the model, and smoothly interpolate between the two at that last token position. I then look at how the LLM’s outputs change as a function of this interpolation in an earlier layer.
When I plot the relative distances of the outputs to the two original sequences, I sometimes see a fairly straight line—suggesting that changes early in the model produce constant changes at the output. But in other cases, I see something more interesting: the outputs barely change at first, then undergo a sudden shift from looking like one sequence to looking like the other, and then stay stable for the rest of the interpolation.
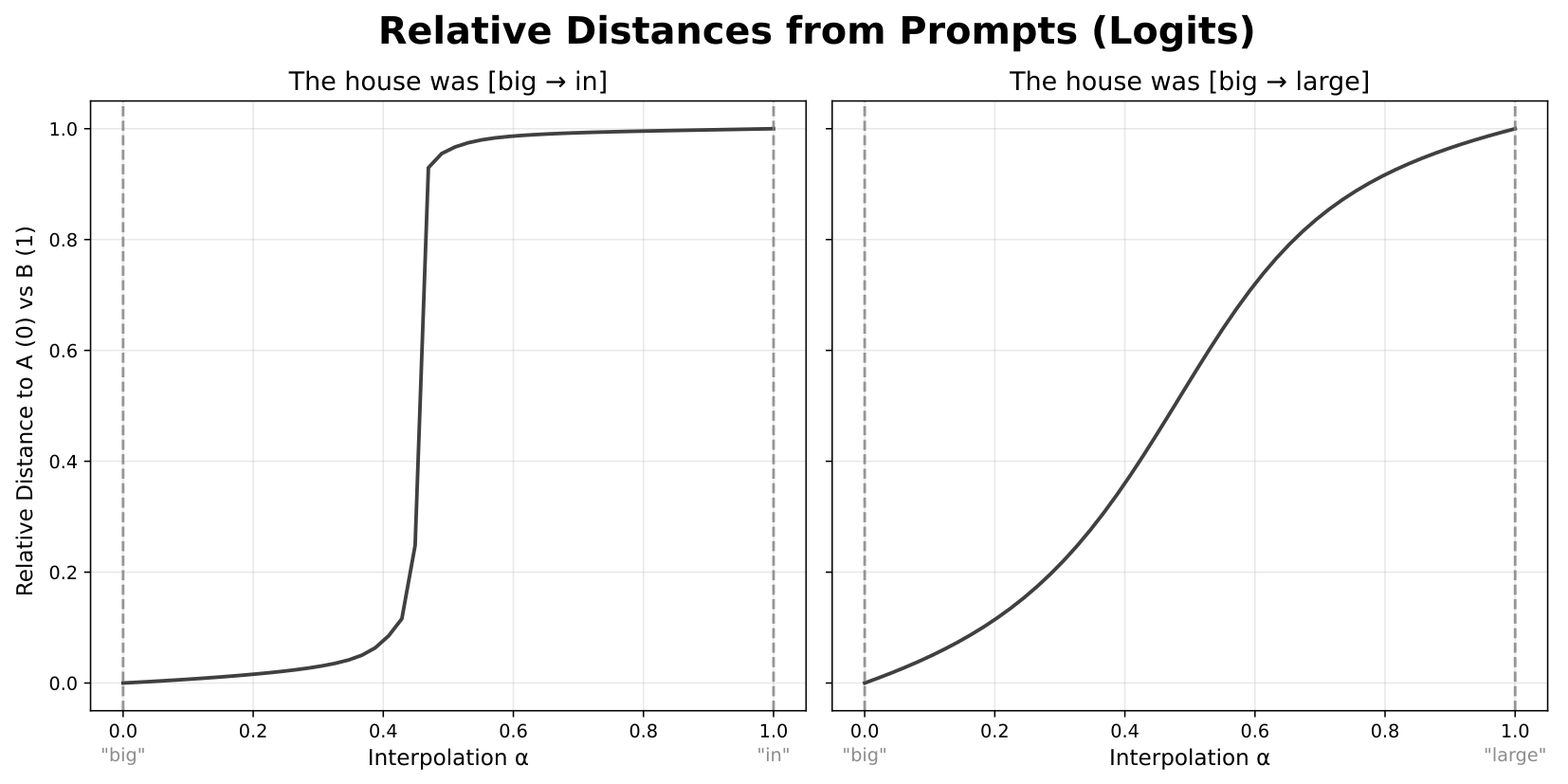
These regions of low change are what I call “plateaus,” and the areas of rapid change between them are plateau “boundaries.” This raises interesting questions about the nature of continuous feature representations—such as the Linear Representation Hypothesis—and has potential implications for interpretability methods like model steering. If plateaus are strongly related to model features, they may also afford new methods for uncovering those features.
So where—and how—do plateaus actually emerge within LLMs? Working with GPT-2 Large, I examined this phenomenon from a variety of different angles: different layers, different components, and different metrics.
Different Layers
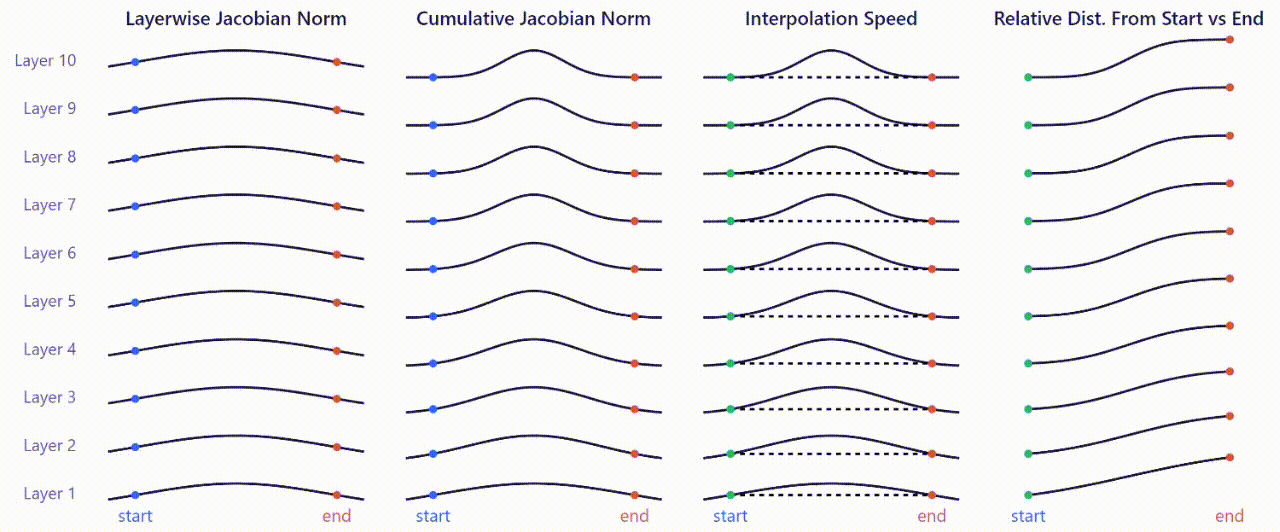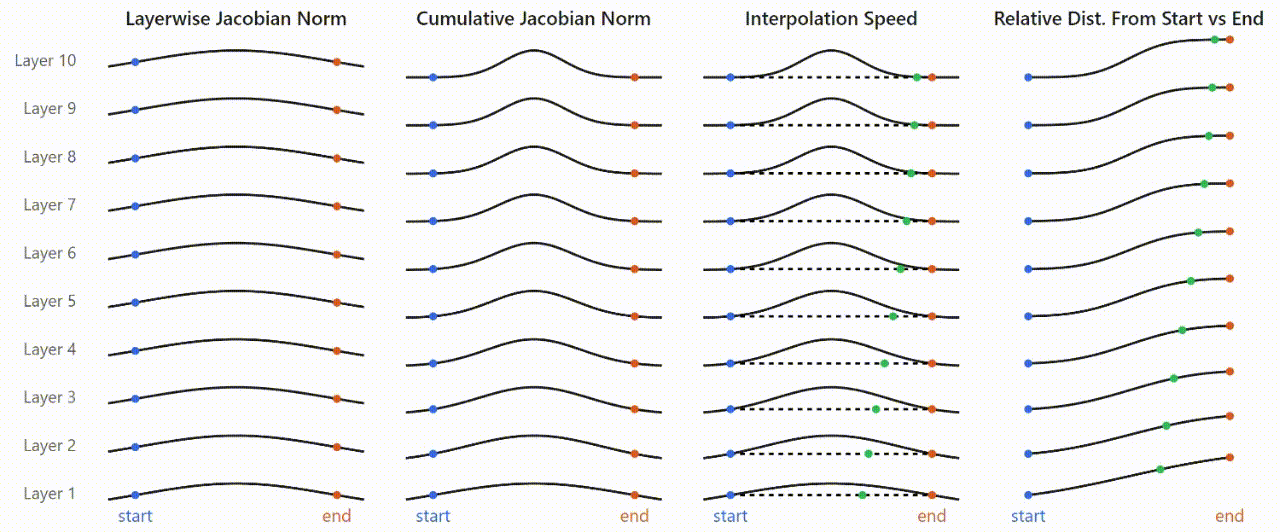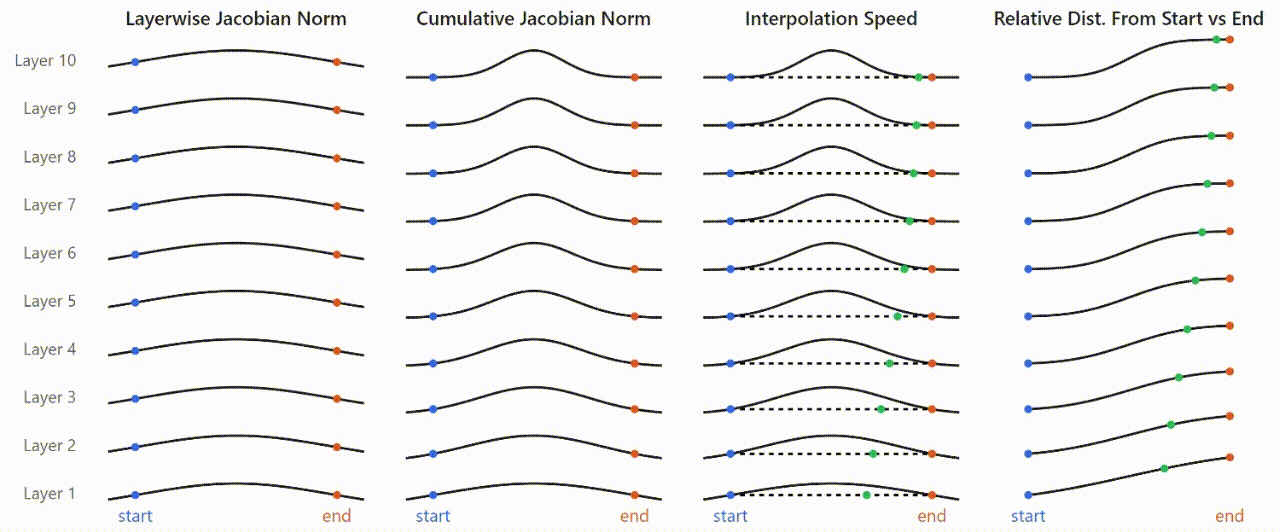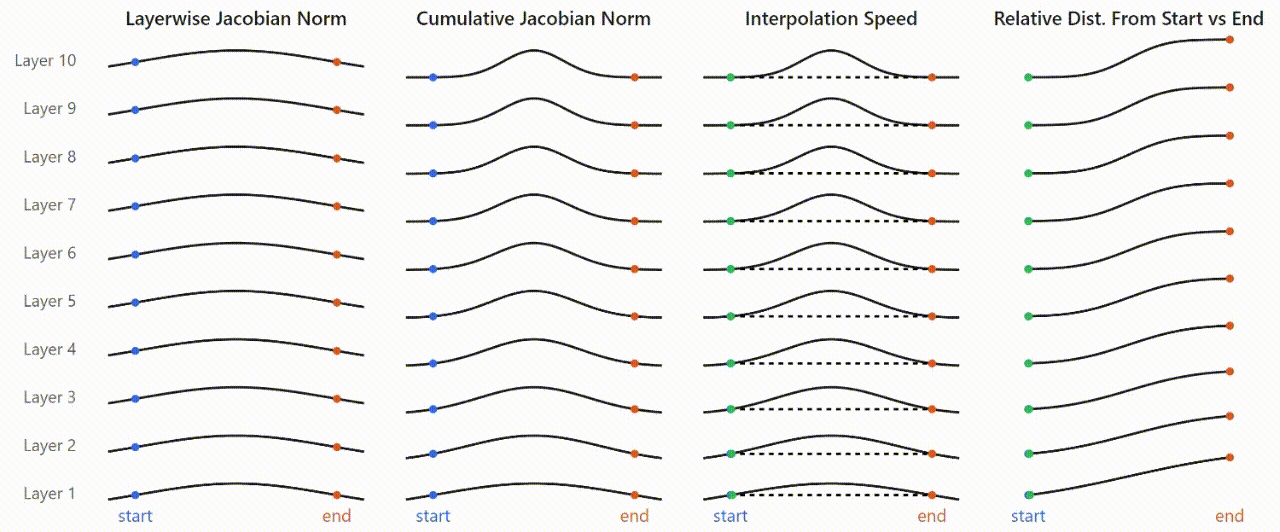
I first looked at how plateaus vary across model layers. Instead of just recording model logits, I recorded activations in each layer downstream of the interpolation and plotted the relative distance curves for each.
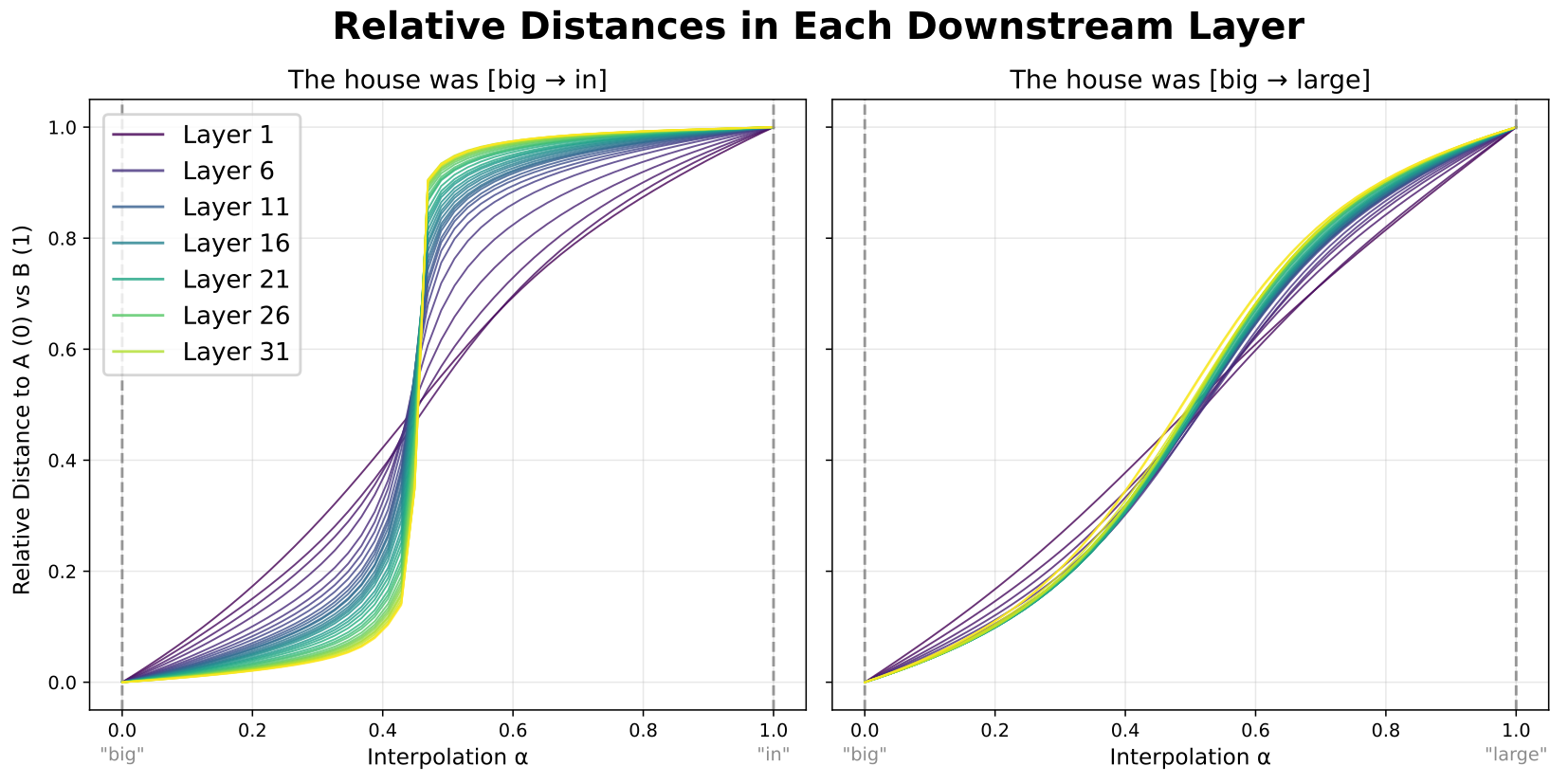
Plateaus emerge and sharpen gradually across model layers, with each successive layer flattening out the plateaus and sharpening the boundary between them. The principal factor turns out to be the number of layers between where you interpolate and where you record—more layers means sharper plateaus. Later layers have a slightly weaker effect, but all layers contribute in qualitatively the same way.
Different Components
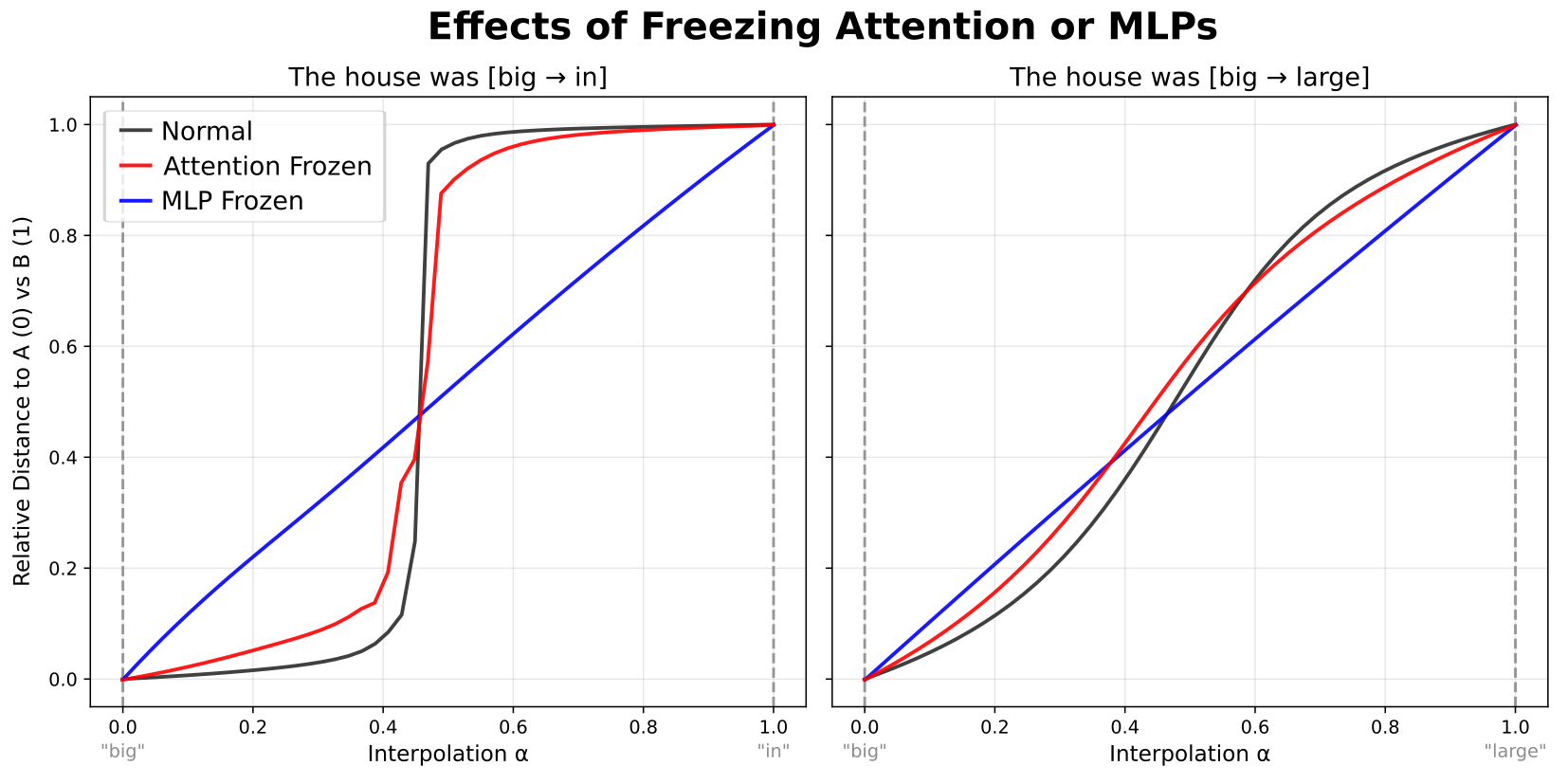
I then asked whether plateaus come from the attention or MLP blocks. By freezing the outputs of each component in turn, I found that freezing attention had relatively little effect, while freezing the MLPs completely eliminated the plateaus. This ties plateaus specifically to MLP blocks—variation in MLP outputs is both necessary and largely sufficient to account for how they emerge.
What is it About MLPs?
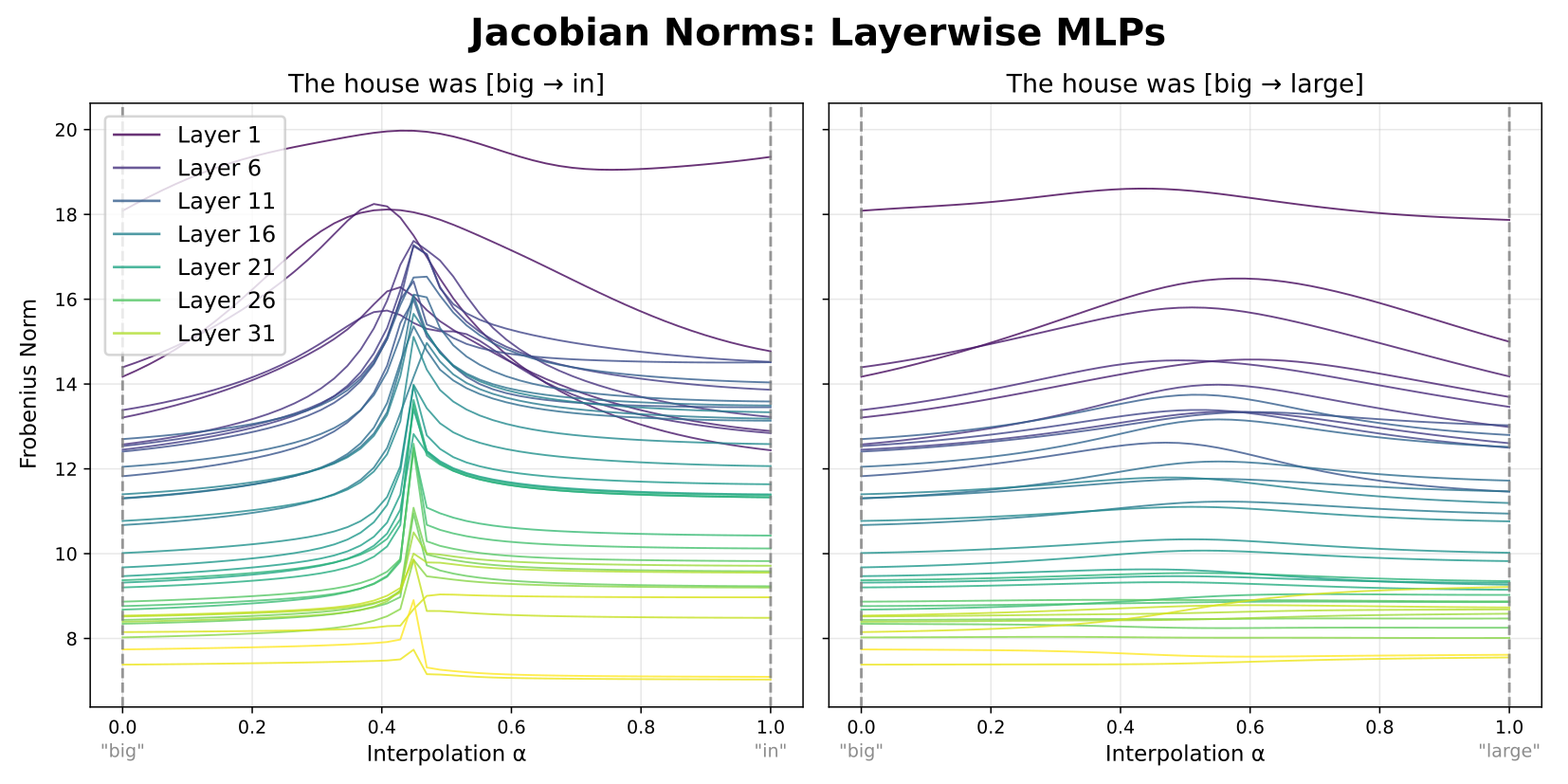
This led me to examine the input-output sensitivity of the MLPs more directly. By computing activation Jacobians at each interpolation step, I found clear spikes in Jacobian magnitude right at the plateau boundaries—exactly where the rapid changes occur. These spikes are broader in early layers but sharpen deeper in the model, consistent with the gradual emergence of plateaus.
Big Picture
The picture that emerges ties everything together: MLP Jacobians are consistently higher in magnitude somewhere along the interpolation path. These Jacobians accumulate roughly multiplicatively across layers, producing sharper and larger peaks at greater depths. Inputs falling in low-Jacobian regions map to very similar outputs (plateaus), and only points in the high-Jacobian region produce substantially diverging outputs (boundaries).
I also found connections to MLP “splines”—decision boundaries for individual neurons. By measuring spline density across the interpolation, I observed a jump in density at plateau boundaries, suggesting that findings from spline-based analyses of classification models may generalize to MLPs in LLMs. These connections to Jacobian-based sensitivity analysis, spline theory, and other active research areas provide promising directions for understanding not just activation plateaus, but model representations more broadly.
The full writeup with additional experiments and details is available as a post on LessWrong, and full code for all experiments can be found on GitHub.